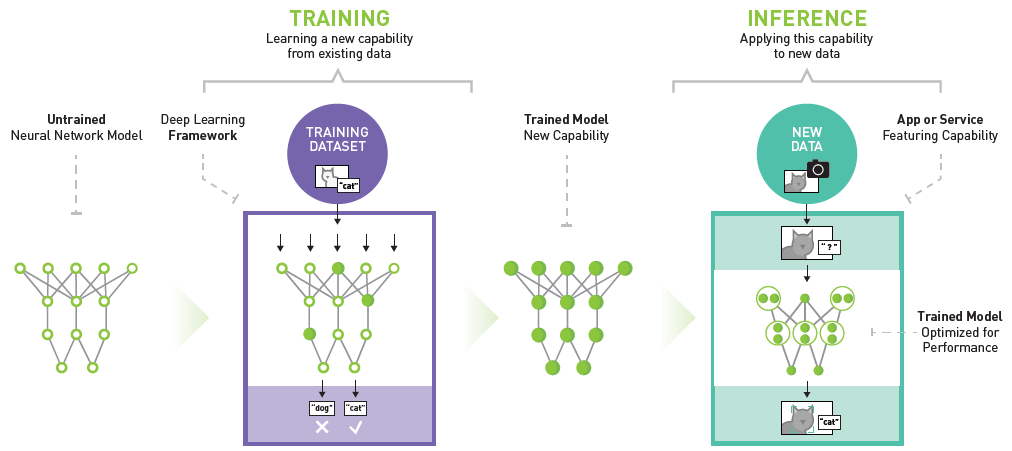
For years, Artificial Intelligence (AI) and Machine Learning (ML) have reshaped industries, empowered lives, and tackled complex global issues. These transformative forces, formerly identified as HPC (high-performance computing), have fueled digital transformations across organizations of all sizes, boosting productivity, efficiency, and problem-solving prowess.
The emergence of highly innovative generative AI (GenAI) models, powered by deep learning and neural networks, is further disrupting the game. Increased use of these data- and compute-intensive ML and GenAI applications is placing unprecedented demands on data center infrastructure, requiring reliable high-bandwidth, low-latency data transmission, significantly higher cabling and rack power densities, and advanced cooling methods.