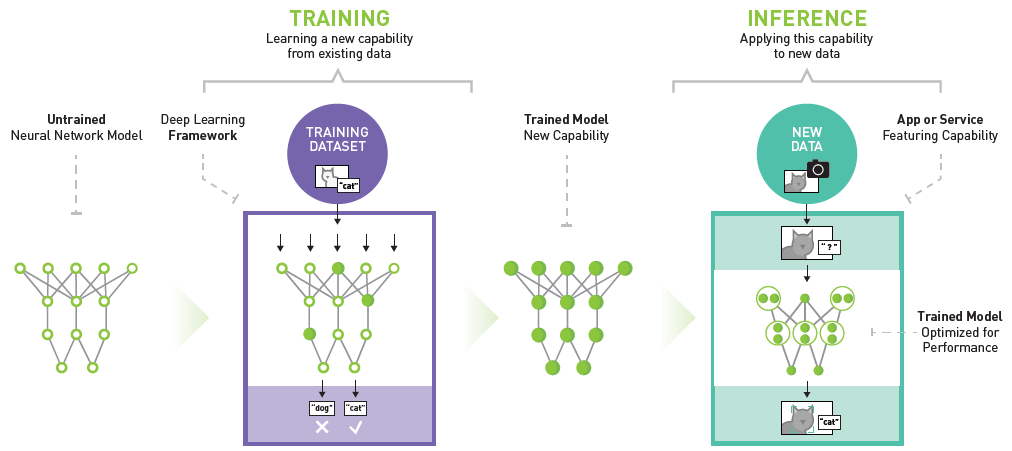
Durante anos, a inteligência artificial (IA) e o aprendizado de máquina (ML) remodelaram os setores, capacitaram vidas e resolveram problemas globais complexos. Essas forças transformadoras, anteriormente identificadas como HPC (computação de alto desempenho), impulsionaram as transformações digitais em organizações de todos os portes, aumentando a produtividade, a eficiência e a capacidade de resolução de problemas.
O surgimento de modelos de IA generativa (GenAI) altamente inovadores, alimentados pela aprendizagem profunda e pelas redes neurais, está revolucionando ainda mais o jogo. O aumento do uso desses aplicativos de ML e GenAI com uso intensivo de dados e computação está colocando demandas sem precedentes na infraestrutura do data center, exigindo transmissão de dados confiável de alta largura de banda e baixa latência, densidades de cabeamento e energia de rack significativamente maiores e métodos avançados de resfriamento.