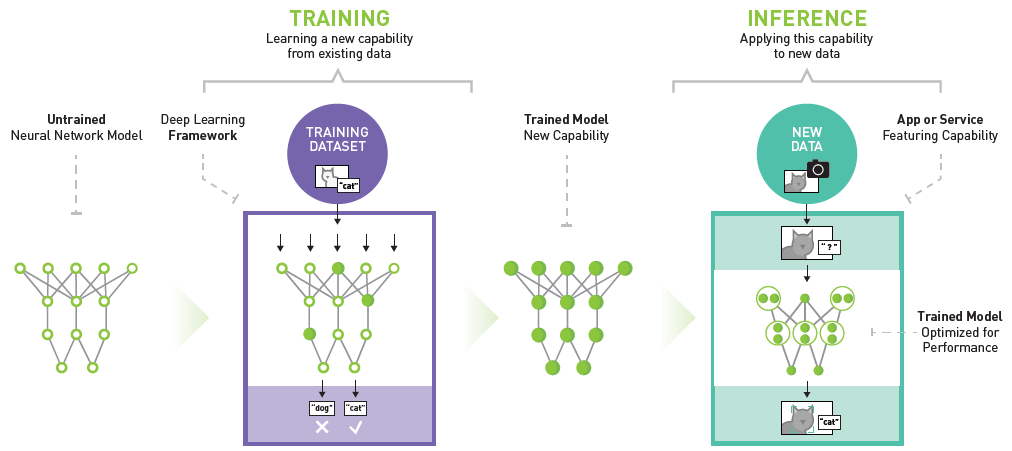
Seit Jahren haben künstliche Intelligenz (KI) und maschinelles Lernen (ML) Branchen umgestaltet, das Leben verbessert und komplexe globale Probleme gelöst. Diese transformativen Kräfte, die früher als HPC (High-Performance Computing) bezeichnet wurden, haben den digitalen Wandel in Unternehmen aller Größenordnungen vorangetrieben und die Produktivität, Effizienz und Problemlösungskompetenz gesteigert.
Das Aufkommen hochinnovativer generativer KI-Modelle (GenAI), die auf Deep Learning und neuronalen Netzen beruhen, sorgt für einen weiteren Umbruch. Die zunehmende Nutzung dieser daten- und rechenintensiven ML- und GenAI-Anwendungen stellt beispiellose Anforderungen an die Infrastruktur von Rechenzentren, die eine zuverlässige Datenübertragung mit hoher Bandbreite und niedriger Latenz, eine deutlich höhere Verkabelungs- und Rack-Stromdichte sowie fortschrittliche Kühlmethoden erfordern.