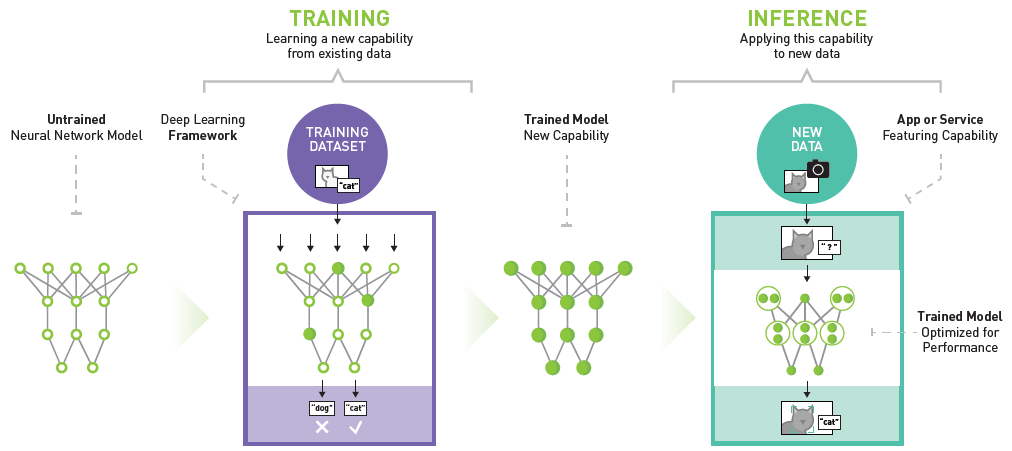
Durante años, la Inteligencia Artificial (IA) y el Aprendizaje Automático (AM) han transformado sectores, mejorado vidas y abordado problemas globales complejos. Estas fuerzas generadoras de cambio, anteriormente identificadas como HPC (computación de alto rendimiento), han impulsado innovaciones digitales en organizaciones de todos los tamaños, aumentando la productividad, la eficiencia y la destreza en la resolución de problemas.
La aparición de modelos de IA Generativa (GenAI), impulsados por el aprendizaje profundo y las redes neuronales, y en general la dinámica en innovaciones de infraestructura de IT, está cambiando aún más el juego. El aumento del uso de estas aplicaciones de Aprendizaje Automático (ML) y GenAI, que llevan a un uso intensivo de los datos y de la computación, está imponiendo exigencias sin precedentes en la infraestructura de los Centros de Datos, requiriendo así una transmisión fiable de gran ancho de banda y baja latencia, densidades de cableado y alimentación de bastidores significativamente mayores y métodos de refrigeración avanzados.