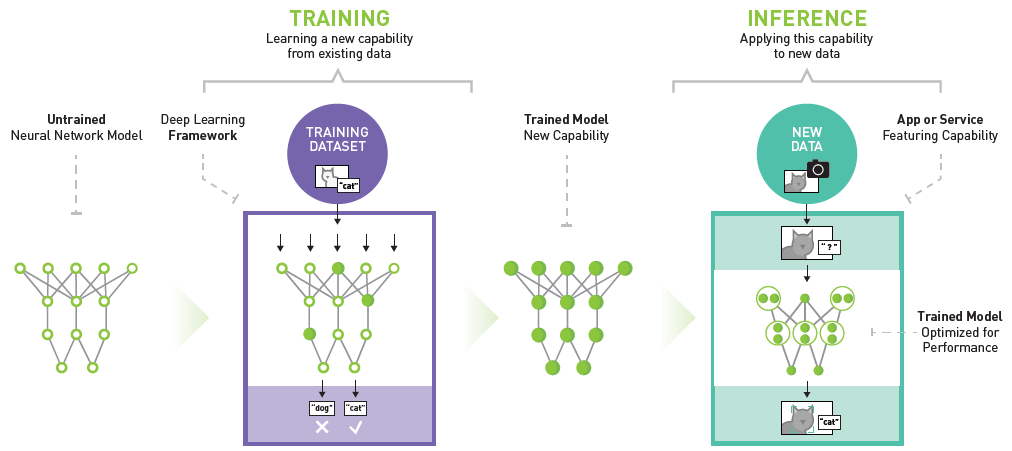
Depuis des années, l’intelligence artificielle (IA) et l’apprentissage automatique (ML) remodèlent les industries, améliorent les conditions de vie et s’attaquent à des problèmes mondiaux complexes. Ces forces transformatrices, anciennement identifiées comme HPC (calcul de haute performance), ont alimenté les transformations numériques dans les organisations de toutes tailles, stimulant la productivité, l’efficacité et les prouesses de résolution de problèmes.
L’émergence de modèles d’IA générative (GenAI) très innovants, alimentés par l’apprentissage profond et les réseaux neuronaux, vient encore perturber la donne. L’utilisation accrue de ces applications ML et GenAI à forte intensité de données et de calcul impose des exigences sans précédent à l’infrastructure des centres de données, nécessitant une transmission de données fiable à large bande passante et à faible latence, des densités de câblage et d’alimentation des racks nettement plus élevées, ainsi que des méthodes de refroidissement avancées.